Diary of a (quickly) delivery feature
July 2013
At The Guardian we have made an effort to adopt continual delivery.
Here is how that works in practice.
++
The task
The task at hand was the common enough requirement to write a simple image proxy server that took at large source JPEG from our origin server and shrink it down to an acceptable size before being sent back to the browser. This would reduce the weight, in kilobytes, and increase the speed of all our webpages.
So we can take a nice high resolution image like this,

... and resize it for different purposes in the design.

Diary
Here's the steps I took to deliver that in to production.
Wednesday
I took over the unreleased image server code from another developer. They had used Scalr, which seemed to produce slightly lower quality images than I was expecting.
I hacked on support for ImageMagick.
Thursday
I did some visual comparison of Scalr and ImageMagick. I was happier with ImageMagick.
I showed the results to the design team, we talked about how the compression ratio was probably a over done for retina screens. I loosened it a little.
Friday
On Friday I updated our CloudFormation scripts, Nginx configuration and deployment scripts and our build server and put the infrastructure in to production after someone reviewed my changes.
Monday
I deployed my branch to production. It broke.
I sit down with our resident sys admin for an hour to diagnose.
We quickly discover that my decision to swap to ImageMagick was a bad one. Having deployed my branch to production I now find that CentOS has poor support for that package.
We fiddle around a bit and decided to move to GraphicsMagick, which seems to work.
Nb. Note here I do not use a clone of the production environment on a virtual machine (I use OSX). Rookie error? Or if I can find and fix an environmental incompatibility problem within an hour does that offset the hassle of the VM upkeep?
Tuesday
I set up some simple monitoring of our image proxy server in Graphite. Not really knowing much about how it would perform I added some graphs for CPU load average, free/used memory and outbound HTTP 200/5xx responses.
I also add a feature switch to the image proxy, so I could turn it on and off quickly outside of a release cycle.
Before I used it with live traffic I asked the sys admins to put a CDN in front of my application.
Wednesday
Today was release day.
Another developer, somewhat more talented at finessing Scala than me, helped refactor the code that wrote our image host names to the HTML.
Testing outside of production is artificial. Fake traffic, fake users, simulated results can only prove so much.
Rather than spend ages load testing in an artificial environment I found the smallest change I could make in production to test my code.
In this case I decided to swap the 140x140px profile images on our contributor pages so that they would hit my new service. These pages only get a small amount of traffic - a few dozen hits p/min.
I configured the image compression service to shrink the JPEG quality a little before sending them out to the browser.

There's a couple of other ways to run these sorts of tests,
- If I was less confident I could have split the traffic and target the change at a small number of people, say 20% of the audience.
- I could have released this particular feature transparently to the end user by including the image on the page but hidden it from the viewport.
I turned on the switch. I sat and watched the graphs I had set up. Everything looked fine.
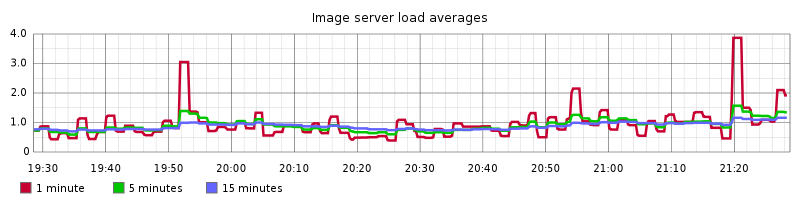
The last task of the day was to configure a basic alert to tell me if anything was broken. Typically we use load balancer latency. If that dropped to an unacceptable level I would get a SMS during the night.
That text message never arrived. I slept soundly that night.
Thursday
After a successful initial release, confident that I was heading the right direction, I merged the code in to our master and redeployed it.
My objective today was to hit the service with a bit more traffic.
In the morning I scaled up the image proxy server stack to twice it's normal size and proxied all our photo galleries. For devices with smaller viewports this shaved about 50% of the download size.
The graphs leapt up a little as you would expect, but well within acceptable levels so in the afternoon I added our set of frontpages, then articles.
At this point 100% of our image traffic was being served off the new service.
Friday
My last task was to write up a short README explaining how it worked and the decision I'd come to should anyone want to pick it up in the future.
Some time later
Of course I'd forgotten a few things, so the server was picked at a bit over the subsequent few months with the odd bug fix and improvement.
After we understood the application's performance requirements we scaled the hardware it back down to an adequate level, after our over-precaution during the initial production testing.
Why this is good for the business
With full control over the software, infrastructure, QA and deployment the speed at which we can build something, ship it, test, diagnose, and mark it as done is very fast indeed. It's a credit to the Guardian development team as a whole that they have built a system that allows people of all skill levels the control and responsibility to this.
Speed is good for business, it saves money.
I made several mistakes during this process, our development process makes it easy to make them, and easy to fix. If all you are ever doing is taking small steps in the right direction then the risks of introducing change are largely mitigated.
Lower risk of breaking things and the faster discovery of problems is also good for business.
Matt's blog about this subject is short and sweet.
At no point did I spend more than a day or two between releasing anything. Once I'd done it I shipped it. Working in small batches means you are more focussed, less likely to accidentally add a whole load of features (Ie. complexity). It's easier for others in the team (engineers, design, QA etc.) to understand and review your work. The planning overhead was minimal.
Focus, simplicity and small provable, predictable deliveries are what businesses want from software teams.
A team of people doing this throughout the year, every day making a handful of things better than yesterday, is an optimal way to deliver software but it's not that easy to keep this pace up in a large(ish) development team and we often get it wrong.
I wrote this to remind myself why we bother.