Modern routing for publishers
July 2017
This describes the evolution of ft.com routing layer over the last couple of years.
++
In the beginning
When you type www.ft.com into you web browser the DNS resolves to our CDN, kindly provided by Fastly - a CDN built on Varnish HTTP Cache.
Varnish gives us a fair bit of programmatic logic in the CDN that has proved useful compared to the traditional "it's just a distributed cache" model.
In a traditional CDN model the request is compared to the cache. If a copy is found then the CDN sends it back to the client, if not the request is sent back to origin. This is great for simple static websites but as latest version of ft.com evolved we ended up with a very dynamic website, one that demanded richer interaction between all our routing components.
So, in this spirit, before the request is sent back to the client each request is proxied to a pre-flight application - essentially an HTTP API responsible for decorating the request headers with several additional fields that are later used by the CDN to route the request.
In Fastly (aka. Varnish, VCL) terms, we are proxying the request to a backend.
Here's some of the things pre-flight does ...
The Access API
For example, if someone requests an article behind our paywall we need to determine whether the person (or otherwise) is authorised to access it.
The pre-flight service forwards the request to the Access API, a service dedicated to knowing the answer to precisely this question - i.e. it's a lookup on the user's subscription status (active, expired, blocked ...), the tier classification of the article (free, standard, premium ...).
But this is multifaceted.
Let's say they are a paying subscriber accessing a standard article, then we need to grant them access.
Or perhaps the person is visiting from a site that we have, for the benefit of marketing, has been granted temporary access based on their referrer (Google, Twitter etc.)
Some of our customer have blanket IP address range access.
One time we opened access to everyone in Miami.
Sometimes, say, around a big event we might remove the paywall entirely for a few hours.
But let's say that person asks for an article that is beyond their current subscription tier (or hasn't got a subscription, or has forgotten to log-in etc.), then we need to deny them access to the article.
Perhaps you have a valid account but your credit card expired on the last payment, or we've detected some anomalies in your account activity and you've been suspended, again a slightly different message.
There's many subtleties to this.
The routing layer is designed for this sort of experimental access to the content on top of it's core function of mediating paid access to our journalism.
In each of these cases the original request header is decorated with an appropriate header.
HTTP/1.1 200 OK
ft-access-decision: denied
The Barrier API
Inside pre-flight, conditionally chained downstream to the Access request is a second request to the Barrier API - a service dedicated to determining the set of offers a user sees if they are denied access to an article.
Offers are things you can purchase, which in our world means annual subscriptions to the articles (in digital or newspaper form).
A person without a subscription might see a set of basic offers.
Perhaps the person already has a subscription but is trying to read something at a higher tier. These folk need presenting with an upgrade message.
Perhaps we've got discounts for you.
All these things will vary on context - like the user location (currency/price, our ability to deliver a copy of the FT in paper form), whether you sit in the IP address range of an existing corporate license.
Again, we append a set headers to the request that represent the above state.
HTTP/1.1 200 OK
ft-access-decision: denied
ft-barrier-type: corporate
ft-corporate-license: 4df8934a-6563-44d8-9787-cb7f6b84d676
ft-country-code: fr
Now were are building a little picture of what the application needs to serve, i.e. ‘a paywall for a person working for a corporation in France'.
We can imagine the sort of application code that could generate something appropriate.
The Segmentation API
In parallel to the access requests we hit a segmentation API, colloquially known as Ammit.
Ammit has a two related purposes - MVT testing (multivariate testing) and traffic segmentation, the former being a subset of the latter.
Both of these features require us to be able to deterministically split traffic into buckets (control, variant etc.) and we can do so on many different factors - geographic location, user-agent, subscription type (standard, premium), or various behavioural models (propensity to subscribe, RFV, as well as combinations of all of these things.
Some segmentation is simple, some relies on calls to APIs.
On the simple side we glean information from looking at request headers (Eg, substring matching the user-agent to segment certain devices), but typically we'll hit another API containing some information on the user's status or their behaviour (Eg, we've an API that tells us how engaged the person is in the product that are accessing, another one that tell us the number of days until their subscription expires).
Each segment can see something different.
Ammit is also backed by VoltDB - a fast, in-memory database for high transactional data volume.
We stream our live ft.com analytics into VoltDB's store in real-time, each event requiring the recalculation of our models, stats etc. we know about the user. This allows us to dynamically adapt the segmentation in near real-time based on the actions of individuals or groups of users.
For example, rather than attempting to detect ad-blocking solely through client-side code, we can build a little behaviour model of what your ad-blocking usage looks like to us over time, across devices, and on top of that build some cohorts and decide whether to prompt you to disable it.
As our products aim to better serve our subscribers through adapting to their individual needs, this dynamism is becoming a key part of the routing layer.
Ultimately Ammit works by figuring out which bucket you belong in and flipping on and off feature flag state in the request header.
Downstream, applications can read these feature flags and conditionally adapt their response based on their value.
HTTP/1.1 200 OK
ft-access-decision: allowed
ft-country-code: fr
ft-flags: big-discount-variant=on, search-enhancements=on, ad-block=off
This user has been picked for a discount and some UI enhancements to the FT.com search box, but we've turned the ad-blocking message off because we don't think they will respond well to it.
The Vanity API
Lastly, in parallel to all of the above we make a request to the Vanity API.
When you type ft.com/world into your address bar we need to translate the 'world' path into a permanent, internal reference to the set of World stories so we can look it up in our APIs (as they don't know what ‘world' means - URLs are related to products not our back-office systems to manage content).
Sometimes we need to do a redirect - Eg, https://www.ft.com/home.
Vanity API does both these things in the routing layer, meaning individual applications don't need to worry about it.
Again, we decorate the request headers with some data to describe what's going on.
HTTP/1.1 200 OK
ft-country-code: fr
ft-original-url: ft.com/world
ft-url: ft.com/section/d8009323-f898-3207-b543-eab4427b7a77
Redirects get sent back to the client immediately.
HTTP Vary
So, pre-flight marshalls all of this information and responds back to the CDN with the original request adorned with lots of extra information.
In effect a set of instructions for the CDN to decide what to do next.
HTTP/1.1 200 OK
ft-access-decision: denied
ft-barrier-type: corporate
ft-corporate-license: 4df8934a-6563-44d8-9787-cb7f6b84d676
ft-country-code: fr
ft-original-url: ft.com/world
ft-url: ft.com/section/d8009323-f898-3207-b543-eab4427b7a77
ft-flags: big-discount-variant, search-enhancements
ft-preflight: true
...
..
.
What we do next is restart the request in the VCL. This sends our request all the way to the back to the start (aka. vcl_recv) along with a flag indicating we've done with the pre-flighting.
Using all this information we can form a cache key, and using HTTP Vary on the corresponding headers we can produce a cachable page, albeit diluted by the number of combinations of the various headers.
Typically, for the high-traffic areas of the site, the results are pleasing.
A cache hit will result in the last good response being sent back to the client, a miss will travel back to our application router.
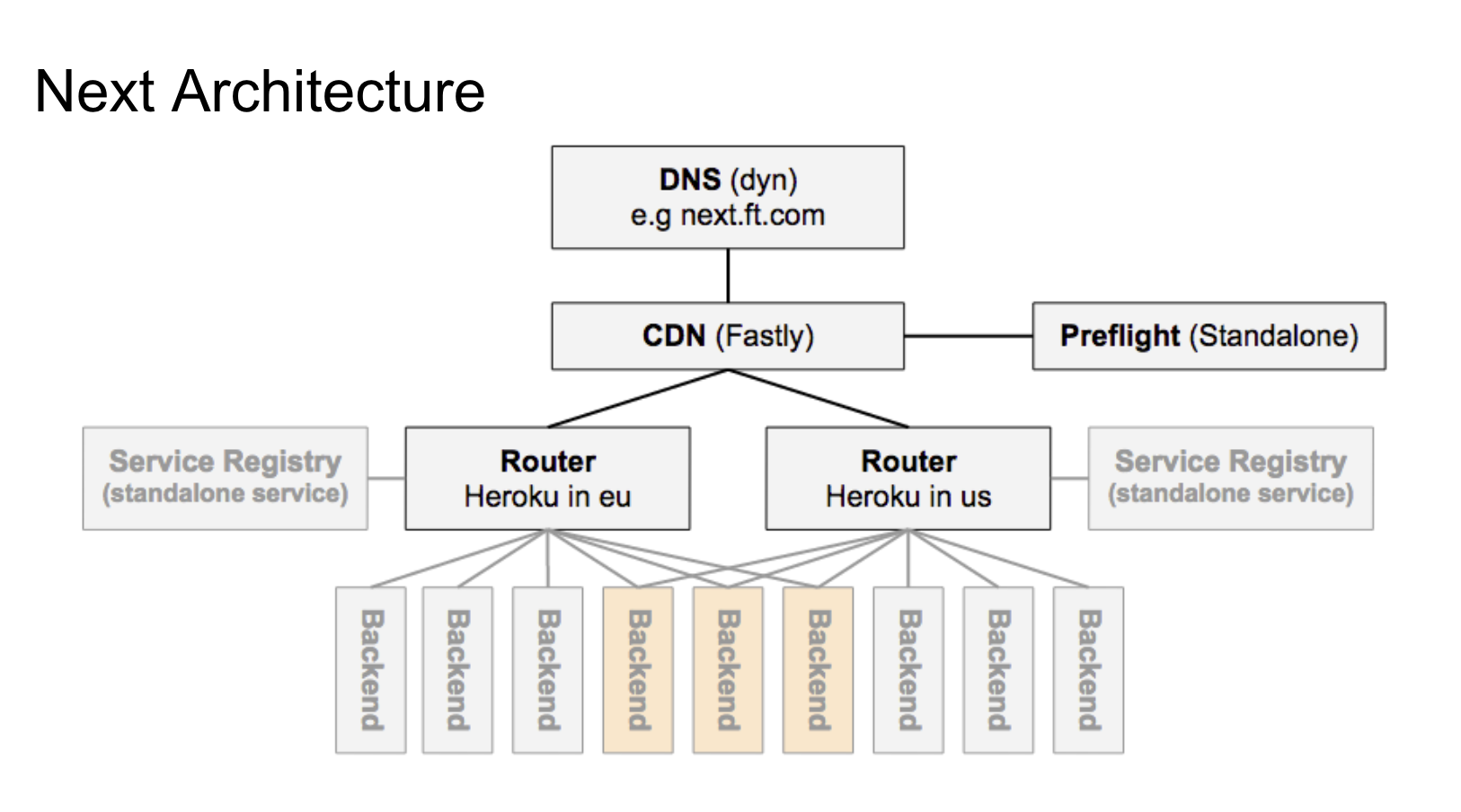
The Router
The second phase of the routing is simpler.
Upon finding the cache empty or expired, Varnish it will proxy the request to our router, another Varnish backend.
The router is a simple Node.js app built on top of it's HTTP module that matches the URL path of the request to a registry of paths and hostnames.
If the requested route matches an entry in the registry the router will proxy the request to that hostname, of failing that send back an HTTP 404.
For example, a request for the following article,
https://www.ft.com/content/27e28a44-51b0-11e7
Will match the registry pattern,
/content/([a-f0-9]+)-([a-f0-9]+)-([a-f0-9]+)
Which has a corresponding hostname,
ft-com-article-eu.internal.ft.com
And so the router sends the request to that server dedicated to serving articles, which is actually a CNAME to a load balancer with a small cluster of servers running, in this case, the FT's article application.
Note also the CDN determines the continent and routes to a geographically nearby router (eu = europe, us = north america etc.)
Upon receiving the request, the application will typically hit some APIs and generate an HTML page, and send it back to the client via the router and CDN.
On a good day all of the above will happen within a couple of hundred ms.
Splitting the routing up into two phases like this keeps our application layer simple. Rather than embedded the logic for access, paywall, MVT testing inside every controller across the stack we do it in one place - each application is effectively being configured by the first phase of routing (pre-flight).
It also keeps our pages faster because requests for pages that result in the same header decoration can be served from the CDN's cache without needing to travel back to the (slower) application stack. Pre-flight is designed to be fast and lightweight.
Thirdly, managing all this state on the server means we can optimise the response to the client, avoiding most of the post-page load adaptations that can cause jank.
It also means we don't need to carry any state in cookies or URLs from page to page beyond the user's session token, much simplifying the application.
Andrew talked about some of this in more detail at Altitude last year.
Thanks to Tom Parker for reviewing this article.