The Cost of a Thing
June 2019
++
It turns out, despite all the hundreds of things we build, the absolute or relative cost of our technical systems is not a well understood number.
Questions like …
- How much did we spend on this?
- Is the content management system more or less expensive than our marketing stack?
- What would we save by stopping this?
- What's the cost of running this in a 'keep it alive' state?
- What proportion of the cost of this system is humans vs other stuff?
- What systems are growing in cost?
... and so on.
Which makes it hard to do your job if you were in charge of a large estate of software.
I spent a few weeks earlier this year researching the cost of various technical systems at the Financial Times with the aim of creating an understandable, replicable means of calculating a total cost of ownership (TCO) and an index to show the costs of our systems.
People + Infrastructure + Contracts
When we think of the cost of building and running software there's dozens of constituent parts.
- The expense of building software.
- Of running the hardware.
- Administering the system.
- Incurred cost of downtime, outage expenses, or security incidents.
- Training people how to use it.
- People that work on it or oversee it - contractors, junior folk, managers.
- Production environments, pre-production environments.
- The costs associated with the gradual decay of software.
- The base business costs - insurance, networking, procurement, business continuity, a desk in an office…
While these are all useful to find the true cost, and precision is a noble goal, in this case I opted for simplicity - a minimal viable calculation of TCO - something that can be calculated in 5 minutes for any system at the FT, aiming for accuracy to the nearest £50k.
So I approximated the cost of by adding the three things that tend to make up the bulk of all system costs, which are people, infrastructure, and contracts.
By which I mean …
- People is the number of human beings from all disciplines that are typical working on this system week to week.
- Infrastructure is the footprint of the system on the platforms it runs on (AWS, Google, private hosting ...).
- Contracts is the cost of vendors the system is composed of.
Each of these approximated to a 12 month time period then summed.
TCO viewed from this perspective is effectively current operating cost per annum rather than lifetime cost - i.e not cost from inception or a future forecast. In this respect it’s not the answer to every question we might have about a system, but a good enough calculation for everyday use.
System: Chicago
If we take a look at the costs of one of our systems - Chicago - we can see the allocation of costs using this technique.
It has a sizeable presence in our data centre, a small number of Amazon services, a large contract (CT-8235), a smaller contract (CT-7836) for add-ons.
The system also has around 5.5 people (3 engineers, 2 system administrators, and a part-time project manager).
| Class | Description | Cost (GBP) |
|---|---|---|
| Infrastructure | Data Centre | £76,144 |
| Infrastructure | AWS | £14,122 |
| Contracts | CT-8235 | £402,452 |
| Contracts | CT-7836 | £29,123 |
| People | ~5.5 people | £406,560 |
| £928,421 | ||
Where to find this information?
Most companies collect data on all these costs but it’s often held outside the view of general staff - sometimes perhaps for confidentiality reasons, sometimes because nobody has ever asked. I’ve not been too precious as to where the data comes from - at the moment it’s a mix of manually exported CSV files, a couple of handmade spreadsheets rather than automated through APIs.
I talked to our legal & procurement teams to get a list of all existing contracts & associated costs - we have 350 or so bits of software that we've bought. Most of them are not standalone and exist as a component of a larger system. Each contract in our procurement database has a forecast that I use as the annual cost (it’s a forecast because costs occasionally fluctuate - Eg. currencies, mid-year contract renegotiations).
For infrastructure costs it’s often as simple as obtaining permissions to view the billing on all your SaaS and PaaS services.
Some platforms have tools to help expose the costs. We use CloudHealth and have a policy of tagging each AWS resource with a unique system code, which help to make cost aggregation across services simple.
If you run your own hardware try to work out a tenancy cost - Eg, cost per host, per rack, storage and so on and use to attribute costs.
For people costs talk to your finance team to calculate a standard day rate per employee that accounts for salaries, taxes, and benefits etc. If you can boil down a staff cost to a simple number you can use it as a multiplier.
For example, three people at £250 p/day (your standard day rate) working for 220 days a year equates to £165k p/annum (3 * 250 * 220).
It’s worth remembering the cost of people might vary for each country your different teams work in.
With this raw information you can quickly apply it to a system of any size to get a broad indication of cost.
All the systems
We made a tool to let people explore the data.
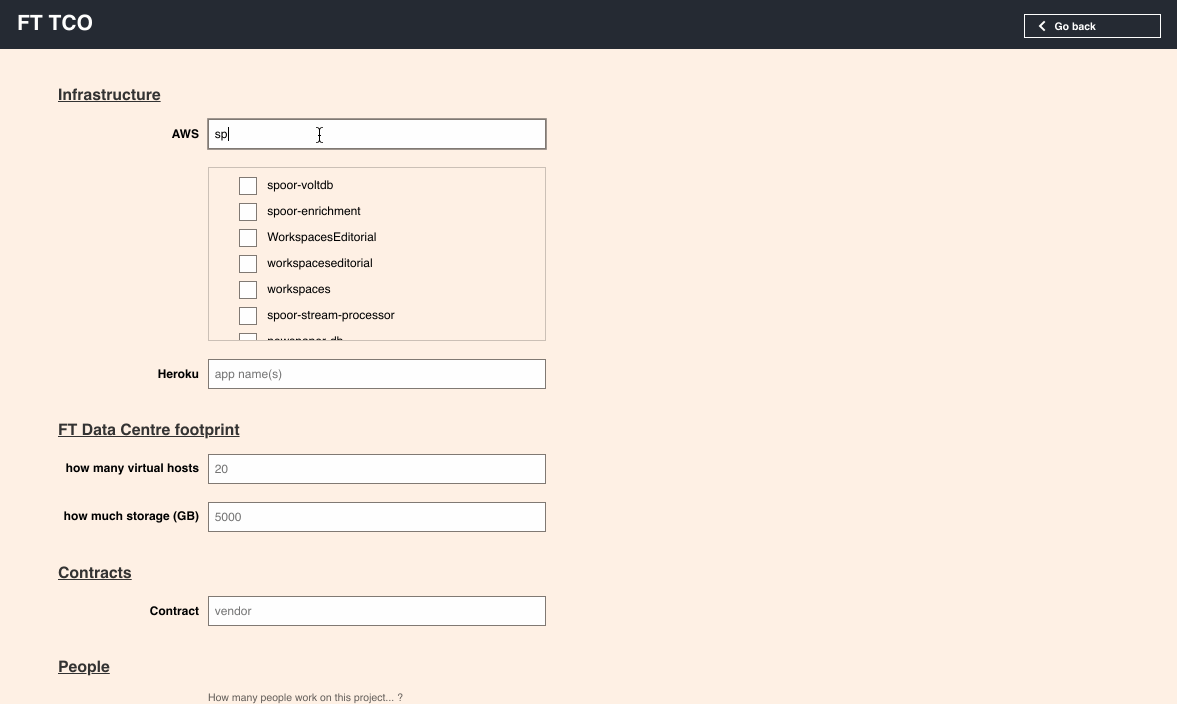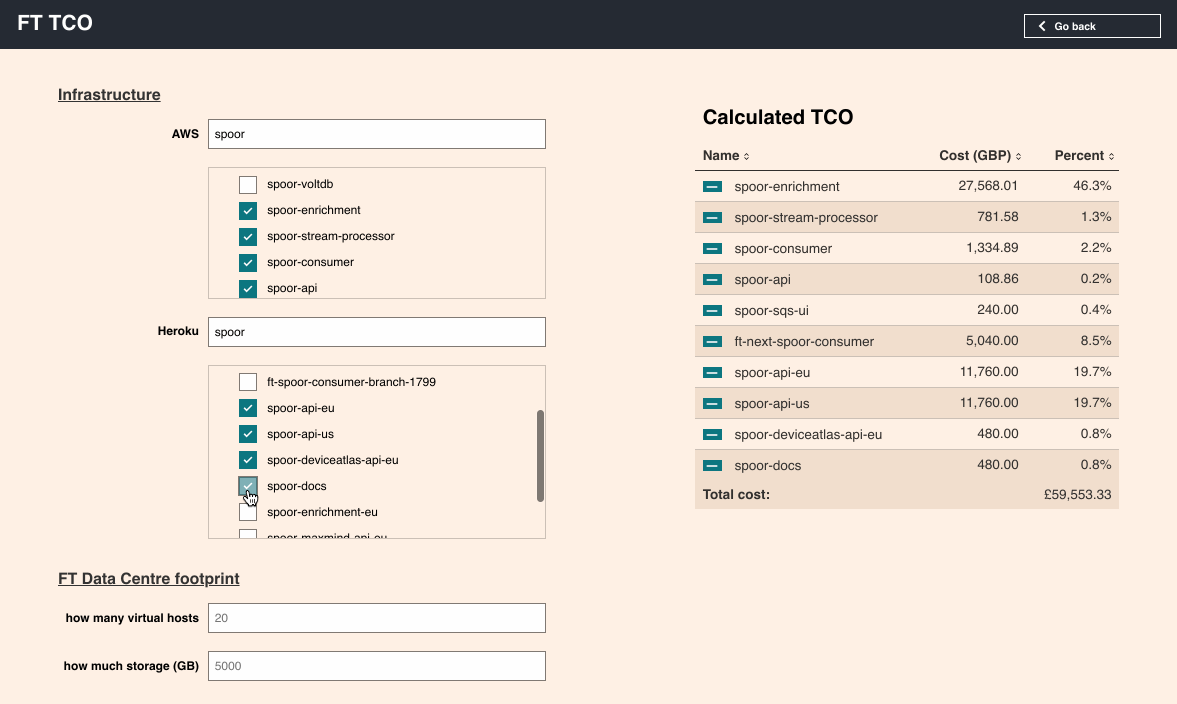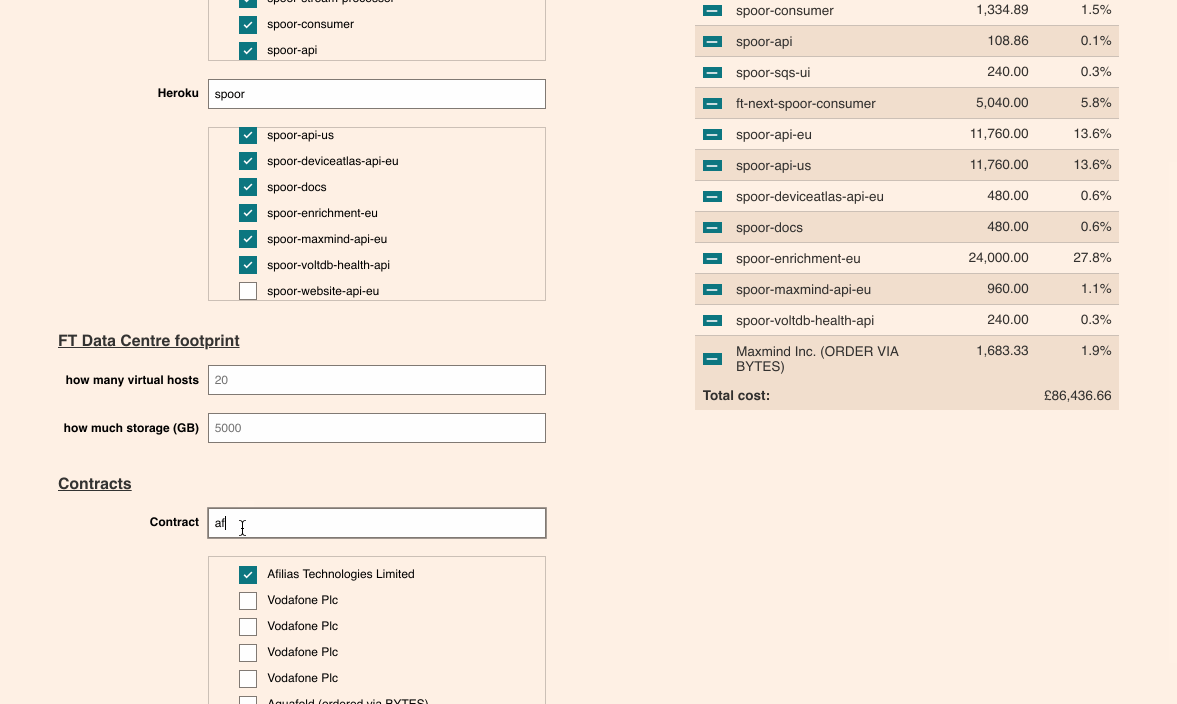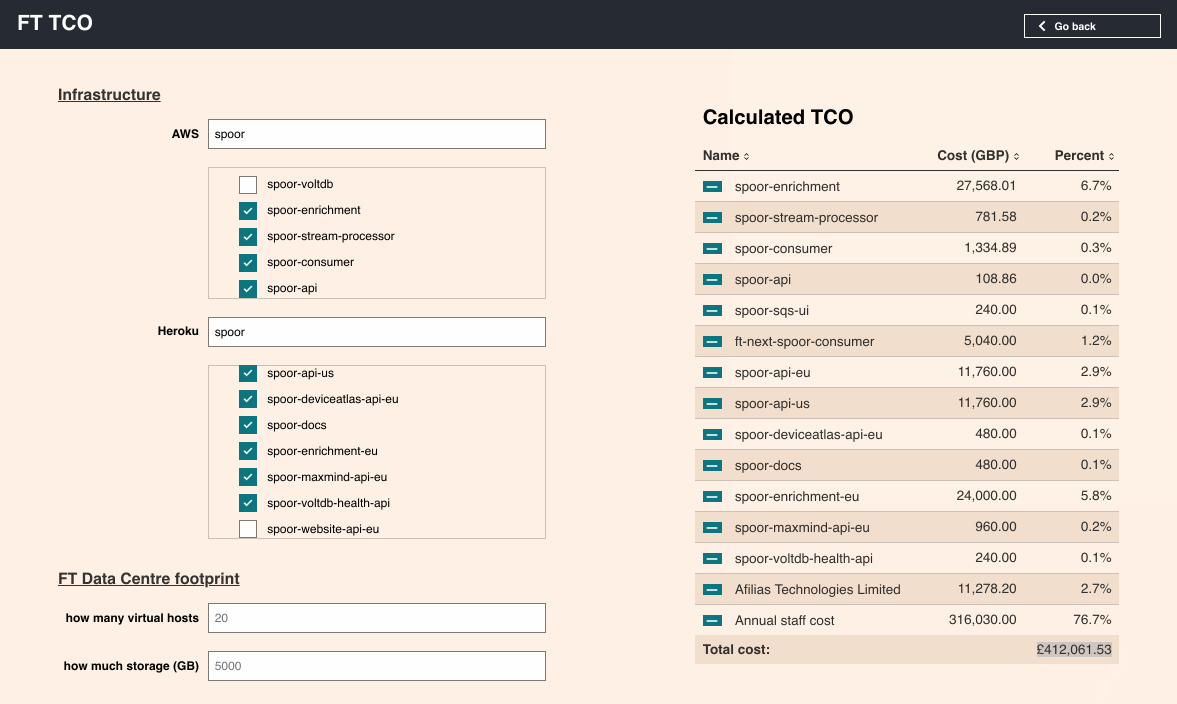
Typing the names of various systems, vendors, and quantities of people allows anyone in the organisation to quickly build an itemised list of how much one of our systems costs.
And running through a few examples allows us to start to compare systems.
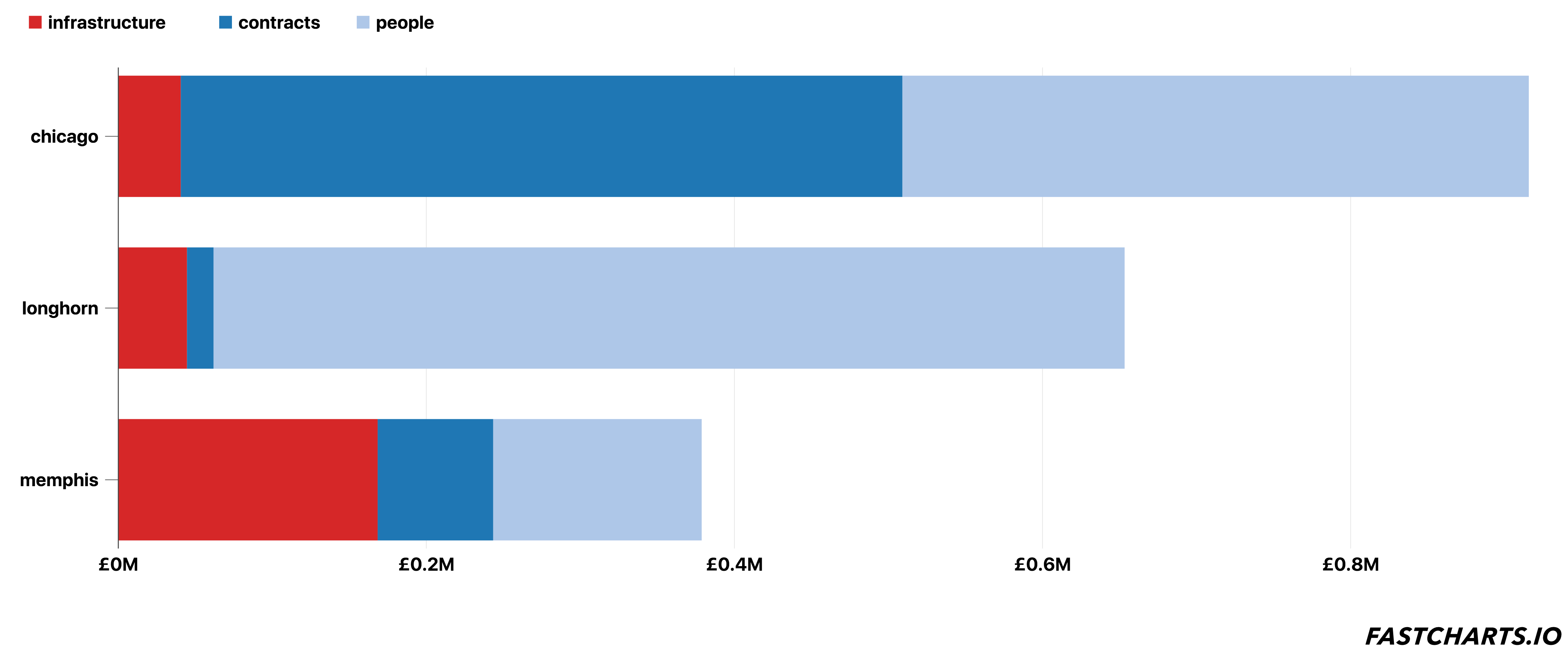
The relative cost of our systems is the most interesting thing.
It helps spot anomalies - a system that has high people or vendor costs, a system that has a strange ratio of people and contracts (high vendor costs = less people normally), infrastructure costs that creep up over time, (surprisingly) cheap systems that people thought were expensive, low vendor costs that might indicate too much bespoke code being written, and so on.
Caveat 1 - What is a system?
The boundary of where a system lies is hard to define. Most systems are connected to each other to provide a service.
There’s two ways I can think to define a system - the first way, and most complicated in my view, is to define the proportional contribution each system makes to a service.
Arguably this is how most people want to think of systems - abstracted from the details of the underlying technology.
But it’s complex - a service like ‘publishing a news story’ for the Financial Times would touch perhaps ~50 different systems, and if each of those systems incurs some cost in providing that service then the calculation quickly becomes multiplex.
The second, simpler, way is to use something akin to Conway’s law, whereby a system is largely defined by the organisational structure that spawned it.
We used the latter definition, so a system at the Financial Times is a thing like a ‘Content API’ or a ‘Newsletter Platform’, which are relatively self-contained.
The upside to this approach is simplicity, the downside is that systems composed of parts of other systems may appear more expensive or cheaper as their costs are hidden in adjacent dependencies.
Our data warehouse is a good example of this - 80% of its costs are derived from the volume of queries that other systems place on it.
One concession we make here is to break some large, shared vendor contracts down by volume - the third-party logging service, the content delivery network can fairly easily be apportioned to other systems by volume.
Caveat 2 - Value judgement
Cost is of course an important contributory factor in the merit of a thing but I'm always careful to point out that calculating TCO is not a value judgement of a system - a £100k system could add as much value as a £1m one.
It’s a natural reaction to look at the expensive systems and think, ‘why?’, but until the costs data is mixed with other data points - both hard data (eg, the system’s contribution to revenue, life-time value etc.) and soft data (eg, the strategic importance of the system, system reports) - it’s hard to take an fully informed view by looking solely at cost.
Also, attribution of value to individual systems when they all work together to provide a service is complicated. So for the moment it’s just helpful for us to understand the costs alone, in isolation of the merit.
A cost conscious culture
In my experience most teams care about the economics of what they are doing.
Generally, we want to build systems that are cost effective, systems that add more value to the organisation than they take to build.
I also think a degree of thriftiness & frugality helps focus a system on what matters in order to fulfil its core purpose - if every new requirement came with a blank cheque we’d end up with baggy, ill-defined systems.
Equally, the Financial Times has an investment in creating a cost conscious culture - funds are limited, we want people to discuss finances & budgets with each other, and we want them understand the impact they can have on these costs, to be accountable for them.
Socialising the cost of system in this consciously over-simplified way supports people feeling more responsible for the money they spend.